
A few weeks ago we made our ‘Availability Plan Template’ freely available on our website and it has now been downloaded many times (several hundred in fact). Making it freely available made us start thinking about all of the organisations Worldwide who have not even looked at establishing an Availability Management process or may be struggling with the concept and wondering where to start. So with that in mind, here’s a little bit of help…'Getting Started With Availability Management'.
Once organisations have established the core processes of Incident, Problem, Service Level and Change Management they will probably want to consider what next. Many organisations decide to look at the Availability Management process. If this is you then you have come to the right place.
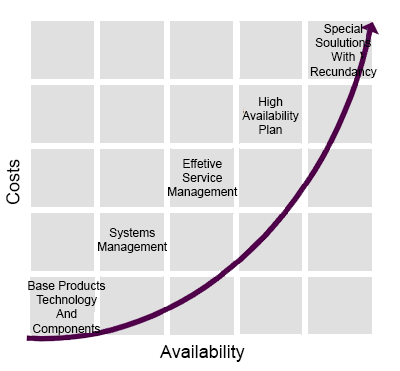
The availability of IT services for most organisations is a key factor, however you do need to decide with your customers exactly what availability means to them and what level of availability they are willing to fund. Unfortunately the default position of many customers is that there should be 100% availability in every service, along with instantaneous change when they desire it and that they should pay nothing (or very little) for those things. Clearly these goals are incompatible.
Copyright © AXELOS Limited 2011. Material is reproduced under licence from AXELOS Limited. All rights reserved
Okay so where do you start with delivering the agreed availability? Firstly it is essential to design your Availability Management process, including purpose, objective and scope, and also assign an Availability Process Manager including a proper description of the role with responsibilities and authority levels (remember this is a role, not necessarily a full time job in most organisations).
Many organisations don’t appoint an Availability Process Manager because they believe (rightly) that availability is part of everybody’s job. The trouble is that if there is no focal point (i.e. an ‘Availability Process Manager), so then what is everybody’s job is also nobody’s job!
You will also need to think of how the process will interface with other key processes such as Service Level Management (SLM), Incident Management and Problem Management.
(Click here if you want to learn more about our ITIL problem management training).
When considering the scope of Availability Management, in an ideal world we should manage the availability of every service. However availability is typically a very in-depth process and not many organisations will have the resources to hand to do Availability Management on every service. Therefore accept that you should begin with the most important services, perhaps adding less important services into the scope of your availability process later.
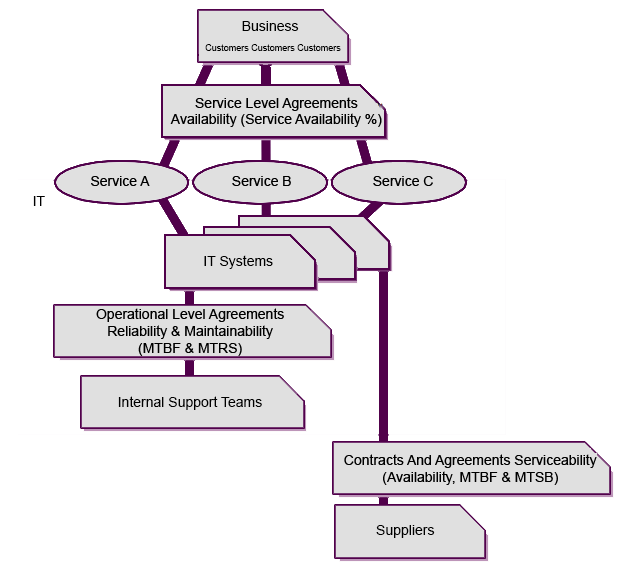
Start initially by establishing the ‘true’ businesses requirements for availability across all of the core and supporting services (those that are in scope). This will mean establishing who your customers actually are (hopefully there is an existing Customer Portfolio, if not one should be created), which services they actually use and what are their realistic, funded availability requirements of each service. Note that most customers will have no knowledge of Enabling Services, only of Core and Enhancing Services. Therefore after establishing the availability requirements of a Core Service, you will additionally need to establish the availability requirements for the Enabling Services.
It will also be necessary to establish exactly what available means to a customer. For example, if all transactions complete in a millisecond that may be deemed to be available. The key question then is “how slow would the transactions be before the customer calls the system unavailable?”. Would transaction completion in half a second be acceptable? What about 20 seconds? What about 20 hours? Obviously somewhere between a millisecond and 20 hours there is a cut-off point after which you can agree that the service is unavailable to the customer, even though it may be technically still be up and running. What about a situation where 99% of transactions complete in a millisecond but 1% take a full minute – is that service available or unavailable?
If customers find it difficult to articulate their availability requirements there are various ways you can help them. One option is to perform a BIA (Business Impact Analysis). The aim here is to decide how long an organisation can survive without that service and what the recovery timescales are. This requires a lot of business and IT input, and needs to be formally documented and agreed. It is not something that takes five minutes but it is important that all stakeholders are involved. Note that the cost of an outage is NOT the same as the value of the service while it is up and running (available), but a BIA can help to focus a customer on what really matters to them. It is certainly true that customers tend to notice unavailability more than availability and so it may help to come at the issue from that angle.
Before you finalise any availability targets with your customers you also need to understand how ‘availability’ is actually delivered to the organisation in terms of an end-to-end service to the customers, so a good understanding of your infrastructure is essential, as in an understanding of how it fits together and how it can be monitored. You will need to establish a monitoring and measurement system (including tools) and agree on availability targets with various support teams through OLAs (Operational Level Agreements) and with the customers through formal SLAs (Service Level Agreements). You can help the Service Level Manager with setting up the availability clauses in the OLAs and SLAs. You should also consider the implementation of a Service Asset and Configuration Management process, if you don’t already have it.
Once the availability target is documented in an SLA, then that becomes the definition of available, i.e. if the service is meeting the SLA target it is available, if it is not meeting the target then it is unavailable even if it is technically still running.
Copyright © AXELOS Limited 2011. Material is reproduced under licence from AXELOS Limited. All rights reserved
(Before carrying on with this post, you may also be interested in this one looking at the question: What Is Change Management in ITIL?)
Another very important point for consideration is the Agreed Service Time (AST) for the service (also documented in the SLA). Downtime (unavailability) outside the AST is not usually reported to the customer. Planned downtime due to approved changes is also not usually reported as the system being unavailable – unless you have agreed a different practice with the customer.
In some customer environments there is a difference between the AST and the Supported Hours. For example the AST may be 08:00-18:00 but the service may only be supported 09:00-17:00. You will need to negotiate with the customer as to whether outages outside the supported hours count as unavailability (which they usually are) and how the duration of an incident that occurs outside the AST is calculated and reported.
Make sure your customers have truly understood any availability targets you have agreed with them in SLAs. Many customers, for example, on seeing an availability target of 99% per week will subconsciously start to think “oh 99%, that is almost the same as 100%, I’m going to get 100% availability!”. Of course this is not correct, many of the future weeks will give them 100% availability but some weeks it will be less, possibly a great deal less. If the customer believes that it will never be less than 99% then what they really want is a guarantee of availability – which is far more expensive to provide. There is a school of thought therefore that suggests that rather than talk to customers about availability targets, we should negotiate with them over how much unavailability they can live with.
Having established an agreed definition of availability and put into place monitoring, the next step is to gather a baseline set of availability measurements. Note that some unavailability might not be directly measurable so also consider using your incident logs to establish if there was any downtime.
If you now know what you are delivering in terms of availability and what has been agreed with the customer for now and in the future, you can do some gap analysis and try to understand where there are any gaps. If there are gaps between what was agreed and what was achieved you will obviously need to make a plan to close those gaps.
If you have established some decent monitoring you should also be able to set up alerts to give you early warning when availability affecting events occur and take preventative actions to minimise the impact and prevent SLA target breaches.
By now you are beginning to manage availability effectively so you need to report what has been achieved. Lack of reporting is a common mistake in availability management. Don’t assume that because you know what you are working to achieve that others also do. Start by establishing an availability reporting procedure. You need to have evidence of what you have been doing and what you have achieved to date, and what you plan to do in the future. So create and start using the Availability plan - (we know where you can get one for free!).
Remember it is a working document, which could be published on a monthly (or other regular) basis alongside the Capacity plan, assuming that someone is doing capacity management of course. You can normally tell if they aren’t because you will be getting a lot of capacity related incidents affecting availability.
A common problem with IT service providers reporting availability is that they have tended to just report on unavailability. Additionally they have tended to report on that unavailability purely in terms of IT specific things, for example “the network was down for 2 hours”. IT service providers need to ensure that their availability reports are meaningful to the customer, for example a better report might have said “the network was down for 2 hours resulting in the loss of £50,000”.
We also need to get better at highlighting the benefits of the services provided. An even better report might have said “the network was down for 2 hours resulting in the loss of £50,000. Prior to that there was 2 years of uninterrupted availability of the network, resulting in £5,000,000 profit”.
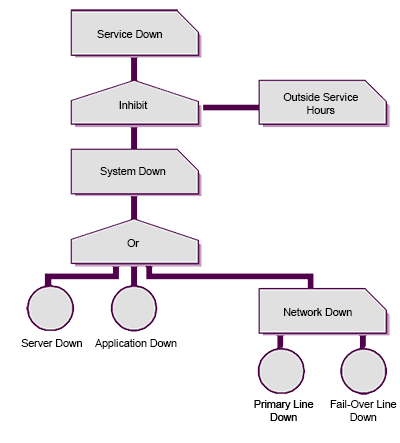
Employing techniques such as System Fault Analysis and Fault Tree Analysis (below) will also help you manage availability levels. Many of the Problem Management Root Cause Analysis Techniques are also useful to investigate. We'll cover this Availability Management technique and others in subsequent blogs... But anyway for now back to availability reporting...
Copyright © AXELOS Limited 2011. Material is reproduced under licence from AXELOS Limited. All rights reserved
Set up an availability reporting framework with clearly identified audiences, their preferred communications medium and the frequency of communication with the audience. Don’t forget to review this reporting framework at least annually.
Next if you aren’t already a member of the Change Advisory Board (CAB), get yourself a place on the CAB so that you can be part of the overall risk and impact assessment of new changes so that you can help minimise failed and disruptive changes whilst maximising the availability benefits of changes.
It is worthwhile reminding yourself that availability is not just your domain, it is a team game. Others will need to be influenced and involved in the process, so regular meetings and reviews should be established – to review availability with support staff and business users who have been or may be impacted. It will be important to get the buy-in of all your stakeholders, particularly those that you are relying on to deliver the availability. Therefore ensure you are able to “sell” the ideas of Availability Management– typically by identifying “what is in it for me” for each target audience.
You will also need to be involved in the design of new services and changes to existing services to ensure that services are design for the appropriate level of availability, resilience and recovery.
If there is a Continuous Service Improvement (CSI) process in place, then your recommendations should feed into it. If not you should consider putting one in place, of course the benefits of doing so will go beyond the availability process.
For many of the improvements you recommend there will need to be a business case, so you will need to learn how to produce a cost benefit analysis and work with the business in establishing metrics like the ‘cost of unavailability’.
Longer term you can help to identify ways to improve supporting processes, such as Incident Management, Problem Management, Service Asset & Configuration Management and others.
Once you have a good grip on Availability Management you can move more and more towards pro-actively managing it, for example by employing a Simian Army as pioneered by Netflix (These are tools for keeping your cloud operating in top form. Chaos Monkey is a resiliency tool that helps applications tolerate random instance failures).
We hope that this short article has been of some use to you and at the very least has got you enthused and started on the road of Availability Management.
Remember that Purple Griffon are happy to assist you in terms of training and consultancy from our ITIL v4 Foundation training course and certification up to much more advanced training and courses.
We also perform mentoring at all levels within an organisation, if you require some guidance/hand-holding initially to get you going.
